正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以 用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
前言
用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、 字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。正则表达式作为一个模板,将某个字符模式 与所搜索的字符串进行匹配。
这里将不会写正则表达式的所有语法,而是常用功能,坑点和解决方案,主要包括
- 日常使用,使用时机
- 高频,高功能用法
- 爬虫使用正则
- 正则原理
- 爬虫举例: 淘宝,京东,1688,当当,拼多多,亚马逊 的商品详情页
- 正则的灾难性回溯现象以及如何解决
“构造正则表达式的方法和创建数学表达式的方法是一样的,好的正则表达式将帮助我们更快的解决字符串问题”
1. 日常工作使用正则处理数据
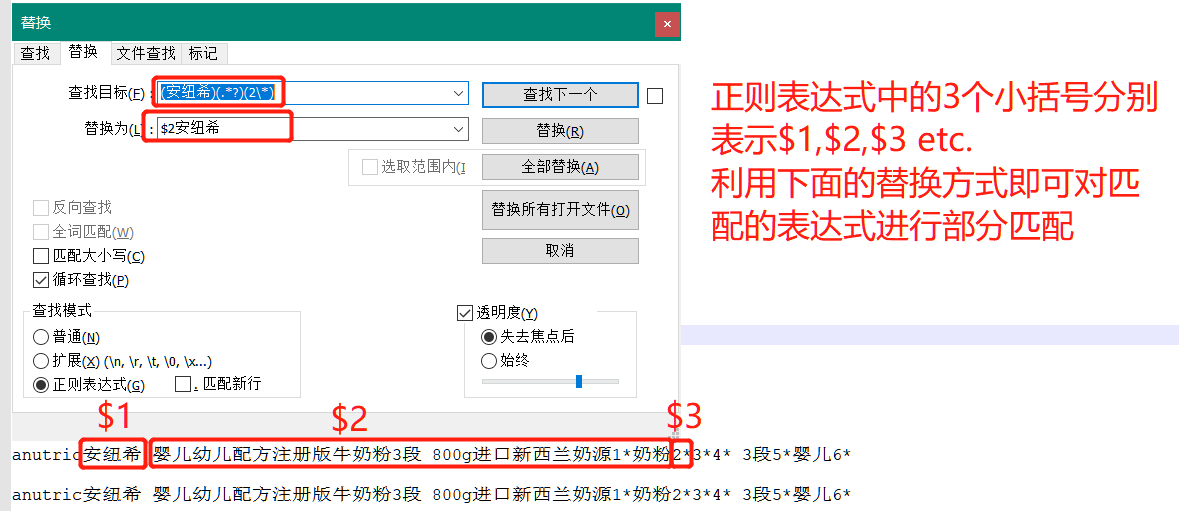
1.1 利用正则表达式中的查找替换在前面添加字符
1.2 爬虫验证网址:

2. 编程语言中使用:
- 懒惰的匹配(最小匹配) : java常用(.*?)来匹配
- 正则匹配中的 group 和 () 相对应
- 工作中常用的转义字符 \
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/**
* 传入正则表达式返回 正则表达式匹配的 第 1 个value :
*
* @param input
* @param regex
* @return
*/
public static String getGroupOne(String input, String regex) {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
if (matcher.find()) {
String result = matcher.group(1);
return result;
}
return null;
}
3.常用正则
- ISBN正则表达式
1
2
3
-- isbn 采用正则表达式来匹配 ISBN 中国的ISBN编号共13位 978为固定 其他十位 第一位为中国的标识7 之后是标识出版社的2-6位数字 之后是出版社内刊物的流水 最后一位是校验位0-9和X
where ISBN regexp '^(?:ISBN(?:-1[03])?:? )?(?=[0-9X]{10}$|(?=(?:[0-9]+[- ]){3})[- 0-9X]{13}$|97[89][0-9]{10}$|(?=(?:[0-9]+[- ]){4})[- 0-9]{17}$)(?:97[89][- ]?)?[0-9]{1,5}[- ]?[0-9]+[- ]?[0-9]+[- ]?[0-9X]$' and receiverarea not regexp '^[0-9]*$'
and receiverarea > 4;
-
18位身份证号码(数字、字母x结尾):
^((\d{18})|([0-9x]{18})|([0-9X]{18}))$ -
域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.? -
常用网站
4.正则表达式原理
4.1正则表达式引擎:
- DFA :对于给定的任意一个状态和输入字符,DFA只会转移到一个确定的状态。并且DFA不允许出现没有输入字符的状态转移
- NFA:对于任意一个状态和输入字符,NFA所能转移的状态是一个非空集合。
https://www.cnblogs.com/AndyEvans/p/10240790.html
4.2贪婪与非贪婪模式;
https://www.jb51.net/article/31491.htm
4.3回溯机制及常见的回溯形式
从问题的某一种状态(初始状态)出发,搜索从这种状态出发所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、不断“回溯”寻找解的方法,就称作“回溯法”.
https://www.jianshu.com/p/458c246d79d4
5.如何使用xpath爬取数据
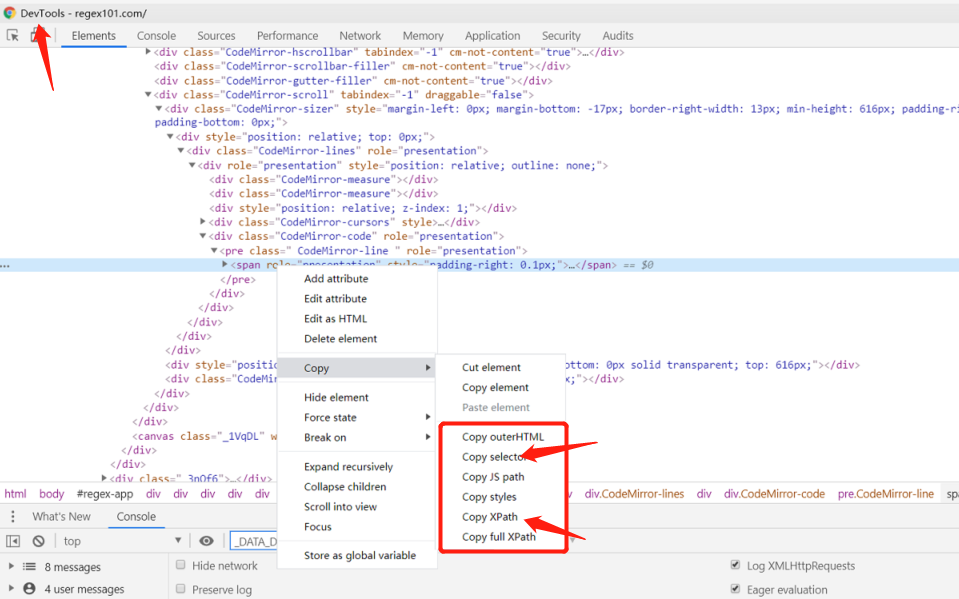
5.1 获取xpath 或者 selector
5.2使用java/python工具类选择文档
1
2
3
4
List<String> urls = page.getHtml().css("div.pagination").links().regex(".*/search/\?l=java.*").all();
List<String> urls = page.getHtml().css("div.pagination").links().regex(".*/search/\?l=java.*").all();
page.addTargetRequests(urls);
// http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/selectable.html
- hutool工具包
- **python **BeautifulSoup4
6.爬取淘宝,天猫,京东,1688,当当,亚马逊中使用的正则表达式
6.1 场景:
场景是知道商品页的情况下,并且已经构造好 ug 和设置好代理的情况 (小象代理),拿到页面只需要解析的情况:
6.2 淘宝爬取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
if (StringUtils.isNotEmpty(json = SystemUtils.get(text, "\\{\"基本信息\":(.*?)}]},"))) {
ArrayList<Map> goodDetail = null;
try {
goodDetail = new Gson().fromJson(json, new TypeToken<List<Map>>() {
}.getType());
} catch (Exception e) {
LogUtils.warn("id:" + extrasParams.get("id").toString() + ",淘系平台json解析异常,json为" + json, e);
map.put(CODE_NAME, "20");
}
if (goodDetail != null) {
for (int i = 0; i < goodDetail.size(); i++) {
Map tmp = goodDetail.get(i);
map.putAll(tmp);
}
}
}
6.3 京东爬取:
1
2
3
4
5
6
7
8
9
10
11
12
for (String pageStr : pageStrList) {
pageStr = pageStr.replaceAll("\\s", "")
.replaceAll("<a(.*?)>", "")
.replaceAll("</a>", "")
.replaceAll("<!--(.*?)-->", "")
.replaceAll("<!--(.*?)-->", "");
//通过regex表达式从详情页获取key,value的值
String pattern = "<lititle=(.*?)>(.*?):(.*?)</li>";
temporaryMap = (LinkedHashMap<String, String>) SystemUtils.getKeyValueAll2and3(pageStr, pattern);
map.putAll(temporaryMap);
6.4 当当爬取:
1
2
3
4
5
6
7
List<String> source = page.getHtml().$(".key.clearfix").$("li:not(:last-child)").replace("<a(.*)\">", "").replace("</a>", "").replace("<li>", "").replace("</li>", "").all();
for (String s : source) {
String key = s.substring(0, s.indexOf(":")).replaceAll("\\s", "");
String value = s.substring(s.indexOf(":") + 1, s.length()).replaceAll("\\s", "");
map.put(key, value);
}
imageList.addAll(dealDangDangImage((String) extrasParams.get("specId"), page));
6.5 1688爬取:
1
2
3
4
5
6
//通过xpath获取1688网页的详情页
String pageStr = page.getHtml().xpath("//*[@id=\"widget-wap-detail-common-attribute\"]/div/div[2]/span").toString();
//通过regex表达式从详情页获取key,value的值
pageStr = pageStr.replaceAll("\\s", "");
String pattern = "data-offer-attribute-name=\"(.+?)\"data-offer-attribute-value=\"(.+?)\"";
map = (LinkedHashMap<String, String>) SystemUtils.getKeyValueAll(pageStr, pattern);
6.6 苏宁爬取:
1
2
3
4
5
String pageStr = page.getHtml().xpath("//*[@id=\"J-procon-desc\"]").get();
//通过regex表达式从详情页获取key,value的值
pageStr = pageStr.replaceAll("\\s", "");
String pattern = "<lititle=\"(.*?)\">(.*?):(.*?)<\\/li>";
map = (LinkedHashMap<String, String>) SystemUtils.getKeyValueAll2and3(pageStr, pattern);